Een grote complexiteit van datamigratieprojecten is de datakwaliteit en dataconsistentie – vooral als er verschillende legacy-omgevingen bij betrokken zijn. Een gestructureerde methodologie en aanpak voor data object definitie, mapping en cleansing regels is nodig. In dit tweede deel van onze data migratie serie, gaan we dieper in op de mogelijkheden van de Talend data kwaliteit toolset bij data migratie projecten.
Vaak is er een mismatch tussen de schattingen en de impact van data migraties als onderdeel van grotere transformatie projecten: Na het evalueren van en het investeren van een aanzienlijke hoeveelheid geld in nieuwe systemen, kan het voorbereiden van data voor een migratie vaak wat minder spannend aanvoelen. Op basis van onze ervaring is het opmerkelijk dat budgetten voor datamigratieprojecten lijken te worden opgesteld op basis van de veronderstelling dat de gegevens bijna perfect zijn. En ook al zijn de kosten van een datamigratie waarschijnlijk maar een fractie van het geld dat wordt besteed aan de aanschaf en implementatie van een nieuw systeem – het is wel een belangrijke succesfactor voor het totale project en de adoptie. Falen met datamigratie en datakwaliteit kan de kosten verveelvoudigen en de waarde van elk project voor uw organisatie minimaliseren. Daarom zijn op het gebied van datamigratie grondige analyse, adequate planning, vroegtijdige betrokkenheid van belanghebbenden en ownership vanuit verschillende bedrijfsgebieden de sleutels tot succes.
Bepaling van de kwaliteit van de gegevens om mee te beginnen
Migratie van gegevens van een of meer applicaties naar andere betekent dat moet worden gekeken naar objecten, gegevensmodel, gegevensstructuur, definities, enz. Deze taken kunnen zelfs nog complexer zijn door datakwaliteitsproblemen die bijna altijd bestaan in legacy-systemen. De meeste datamigratieprojecten blijken dus datakwaliteitsprojecten te zijn en bieden ook een kans om naast de migratie-inspanningen een toekomstbestendige data governance-strategie op te zetten.
Audits gegevenskwaliteit – ken uw startpunt
Naast een inventaris (gegevensbronnen en te migreren objecten, hun dictionary en gegevensmodel) en een schatting van het volume, kan een snelle controle van de gegevenskwaliteit helpen om een realistische schatting te maken van uw migratie-inspanningen. Begin al in een vroeg stadium van uw project met het profileren van de gegevens in uw legacy-systemen. In dit stadium heeft u misschien nog geen toegang tot een volwassen ontwerp voor het doelsysteem en kunt u zich misschien nog niet concentreren op de specifieke gegevensvereisten van uw nieuwe systeem. Niettemin zou u nu al moeten weten dat bepaalde (master) data objecten zoals klantinformatie, product attributen, enz. in scope zullen zijn en een vroege kwaliteitsaudit van het legacy systeem kan verder worden gedetailleerd en verbeterd tijdens toekomstige project iteraties.
Talend Data Quality
Met een complete toolset van datakwaliteitscomponenten kan Talend een migratieproject direct vanaf het begin ondersteunen.
- Met dataprofilering kunt u rapporten over datakwaliteit maken en uw oude gegevens analyseren en al een eerste inzicht in de datakwaliteit krijgen door een analyse van het volledige volume uit te voeren.
- Door regels voor het opschonen, matchen en consolideren van gegevens te definiëren, voorkomt u dat vuile gegevens naar de nieuwe systemen worden verplaatst. Automatische matchingalgoritmen en machinaal leren kunnen worden gebruikt om duplicaten en gouden records te bepalen en overlevingsregels toe te passen.
- Eigen verantwoordelijkheid en governance inzake gegevenskwaliteit kunnen worden ondersteund door het gebruik van toepassingen zoals de data stewardship console en data prep tooling – waarmee gebruikers in een Excel-achtige toolset kunnen werken om verdachte records te controleren en op te schonen in combinatie met geautomatiseerde opschoningsregels.
- Logging van opschoning- en transformatieacties kan worden gebruikt om een algemeen controlespoor voor uw migratieproject te genereren om de voortgang te volgen en aan de compliancy-regels te voldoen
Voorbeelden uit onze dagelijkse praktijk
Een van de use cases waar we recent aan hebben gewerkt is de consolidatie van een product hiërarchie over verschillende legacy applicaties. De uitdaging was om een mapping te maken van lokale variaties naar een globaal hiërarchiemodel met opgeschoonde productstamgegevens die worden toegepast voor geconsolideerde rapportage.Elk product (item) moet worden gemapt naar de Master hiërarchie. Om de zaak te vereenvoudigen, beginnen we met een eenvoudige hiërarchie van 2 niveaus, waarbij de mapping moet worden uitgevoerd voor elke categorie die in de gegevens aanwezig is.
Voorbeeld: Product Master Data Consolidation
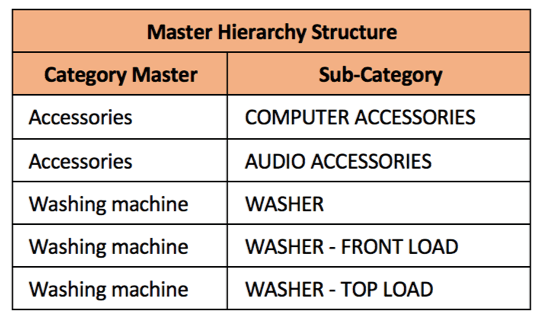 |
Laten we eens kijken naar een eenvoudige hiërarchische hoofdstructuur voor productcategorieën. |
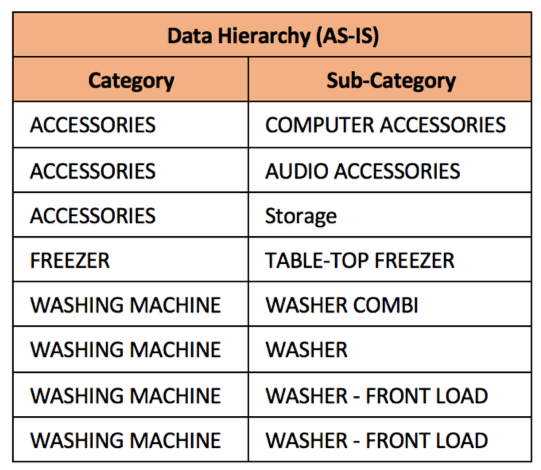 |
In vergelijking met een andere producthiërarchie die in een van de oudere toepassingen bestaat, zijn de verschillen gemakkelijk aan te wijzen. |
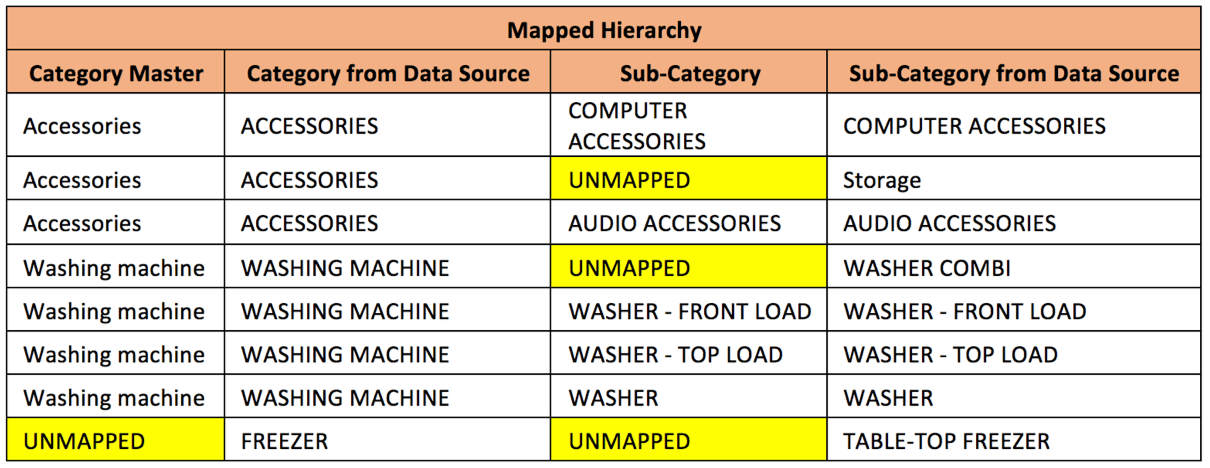
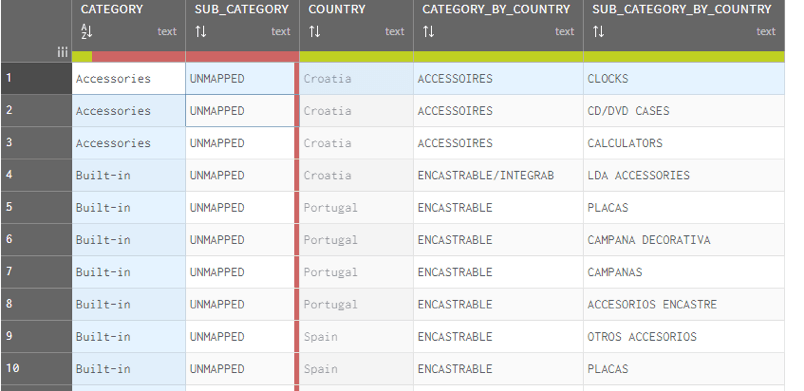
| De hiërarchie wordt in kaart gebracht en de ontbrekende / niet in kaart gebrachte items ten opzichte van de hoofdhiërarchie worden gemarkeerd: | |
 |
|
De “UNMAPPED” staat voor de velden (Categorie of Subcategorie) die niet voorkomen in de hiërarchische hoofdstructuur. Die niet-toegewezen velden moeten worden gevalideerd door functionele gegevenseigenaars (KMO’s / Data Stewards).
Betrokken voorbereidingsstappen
- Identificeer verschillende combinaties van categorieën/subcategorieën uit de gegevensbronnen
- Breng de producthiërarchie van de gegevensbron manueel in kaart met die van de masterstructuur
Met behulp van Talend Data Integration (DI) werd de “UNMAPPED” gegevenshiërarchie blootgesteld aan de Talend Data Stewardship (TDS) Console.
- De SME’s of Data Stewards moeten ervoor zorgen dat een geldige categorie (en subcategorie) wordt ingevuld in plaats van de “UNMAPPED”.
- De Stewards valideren de hiërarchie en lossen problemen op door een geldige categorie/subcategorie te taggen
- Zodra de hiërarchie mapping is voltooid in de TDS console, is de volgende stap om de doelgegevens bij te werken om de juiste / nieuwste hiërarchie te bevatten met behulp van Talend DI opnieuw.
|
|
|
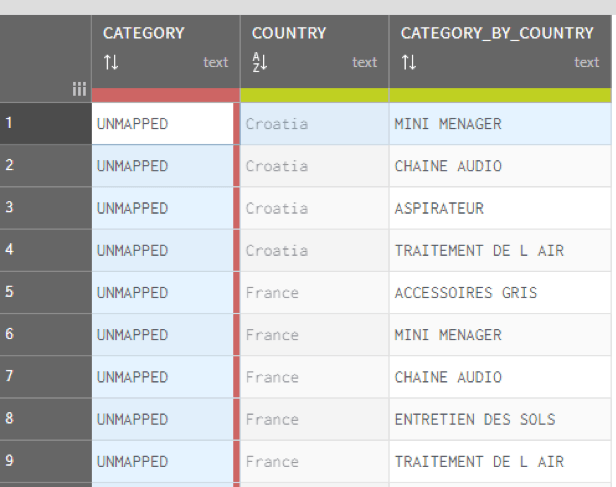
Analyse van productgegevens – Identificatie van Discrepanties & Golden Records
Naast het opschonen van de producthiërarchie, moeten ook de attributen van de productstamgegevens in de gegevensbron worden gevalideerd voor datakwaliteit. De gegevens moeten worden ingedeeld in de volgende discrepantieclassificatie:
- NULL velden
- Duplicaten (Numeriek/ Referentiekenmerk)
- Ongeldig (specifiek voor kenmerken zoals streepjescodes/ GTIN)
- Duplicaten op basis van productbeschrijving (de beschrijving kan verschillend zijn, maar het product in verwijzing kan hetzelfde zijn)
Uitgangspunt is de creatie van een unieke identificatiecode per record om een audit trail te creëren voor eventuele wijzigingen, consolidaties en transformaties. Een sequentieel ID voor elk record is voldoende om ze later gemakkelijk te identificeren. Met behulp van Talend DI en DQ componenten worden brongegevens gerepliceerd in meerdere streams om vergelijkbare bewerkingen uit te voeren over meerdere attributen:
- Identificeer NULL waarden
- Duplicaten op attribuutniveau identificeren door de gegevens te groeperen volgens de attribuutwaarde en door de gegevens te filteren die meer dan 1 instantie voor dezelfde attribuutwaarde hebben
- Valideer gestandaardiseerde identificatiemiddelen zoals barcodes:
- NULLs
- Duplicaten
- Ongeldigen (b.v. op basis van lengte, niet-numerieke tekens, onjuiste controlecijfers)
- Patronen (DQ Profiling perspective)
- Consolideer discrepanties voor alle attributen.
- Creatie van bijkomende kolommen/attributen om te identificeren:
- Type discrepantie (NULLs, Ongeldig, Duplicaat)
- Discrepantie Attribuut/Veld (Attribuut binnen bereik voor die specifieke gegevensrij)
- Mapping van de producthiërarchie master naar de discrepantietabel voor rapportage en statistieken
Golden Record Identificatie
- Vergelijk de invoerbronnen met de vastgestelde discrepanties om de resterende records eruit te filteren. Deze overblijvende records/gegevens moeten verder worden geanalyseerd.
- Duplicaten identificeren op basis van productbeschrijving
- Gebruik van geïntegreerde fuzzy logica en algoritmen met Talend DQ
- Unieke, dubbele en verdachte records dienovereenkomstig scheiden
- Duplicaten samenvoegen
- Verdachte records worden aan gegevensbeheerders verstrekt voor verdere analyse. Feedback wordt ook gebruikt om de algoritmen voor deduplicatie te wijzigen en te verfijnen.
- Unieke records die niet onder een discrepantie vielen en daarom als “Gouden Records” worden geclassificeerd
Rapportage
Tijdens alle verwerkingsstappen worden bewerkingen gelogd op recordniveau. De resulterende logboektabellen kunnen gemakkelijk worden geraadpleegd om te komen tot meerdere rapportage-indelingen. Aangezien alle uitvoergegevens worden afgezet tegen de hoofdproducthiërarchie, kunnen statistieken gemakkelijk worden uitgesplitst op land-, legacysysteem- of categorie-/subcategorieniveau om de gegevenskwaliteit op een granulair niveau te bepalen.
Dit is een vereenvoudigd voorbeeld uit onze dagelijkse praktijk. Het belangrijkste voor ons is om een migratie framework te creëren dat niet alleen eenmalig kan worden gebruikt, maar ook kan worden overgezet naar een nieuwe omgeving om de gegevens schoon en in-sync te houden.
Data Governance: Behoud van datakwaliteit na migratie
Datakwaliteit is een voortdurende inspanning. Nadat u aanzienlijke investeringen hebt gedaan om ervoor te zorgen dat gegevens van hoge kwaliteit in uw nieuwe systemen worden ingevoerd, is er een goede gelegenheid om datakwaliteitsprocessen in te voeren om de migratie-inspanningen te benutten. Door het onderhoud van data te beheren en data die tussen verschillende systemen bewegen te monitoren, behoudt u de controle. Als u van plan bent te investeren in een tooling voor datakwaliteit om uw migratie te helpen voltooien, zorg er dan voor dat monitoring- en rapportagemogelijkheden worden opgenomen om de kwaliteit van uw data na de migratie te handhaven.